Overview
This guide builds an agent that takes a company name and returns a citation-grounded VC investment memo with seven sections: Snapshot, Team, Financials, Product, Market, Risks, and a Thesis ending in a one-line recommendation. Every claim is traced back to a primary source. It runs on the Perplexity Agent API and its built-inweb_search and finance_search tools, orchestrated with LangGraph, and evaluated in LangSmith. The whole build runs in about ninety seconds for roughly $0.40 per memo.
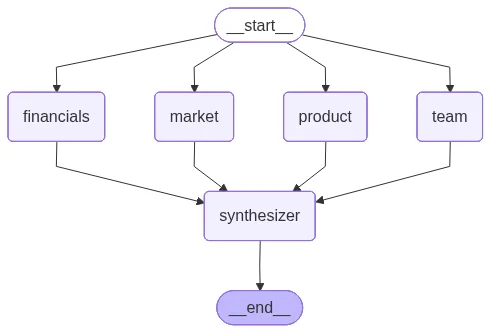
The design lesson generalizes beyond finance: separating search from synthesis is a structural reliability fix for a research agent. Four research nodes fan out in parallel, each calling the Agent API with its own tools. A final synthesizer node has no tools and can only cite evidence the research nodes already gathered, so the memo cannot invent a source.
Features
- Parallel research fan-out. Four focused research nodes (team, financials, product, market) run concurrently, each with its own tools and search budget.
- Tool-less synthesizer. The final memo is composed only from upstream evidence, a structural guard against fabricated citations.
- Built-in Agent API tools.
web_searchandfinance_searchwork out of the box; no client-side search plumbing for the core agent. - Auditable in LangSmith. Every node’s tool calls and outputs are captured, so any claim traces back to the search result that produced it.
- Provider eval harness. A LangSmith comparison that scores search providers on primary-source rate, financial-concept coverage, latency, and cost.
Prerequisites
- Python 3.10+
- A Perplexity API key (
PPLX_API_KEY) - A LangSmith API key for tracing and evaluation
- (provider comparison only) Parallel and Exa API keys
Setup
Build the agent
Everything in this section goes in one file. Paste the blocks in order intomemo.py and you have the complete agent.
Graph state
Each research node readscompany from the shared state and writes its findings into research_output; a reducer merges the parallel writes.
Models and tools
The Agent API exposes Perplexity’s built-in tools directly. The financials node addsfinance_search; the rest use web_search. max_steps caps each node’s internal search loop, which is the per-node search budget.
Research prompts
One prompt template serves all four nodes; per-section guidance steers what each node hunts for and which sources to prefer.Research nodes
All four nodes share one runner: a single Agent API call with that node’s tools and search budget. The API runs the search loop server-side, so there is no client-side tool plumbing here.The synthesizer
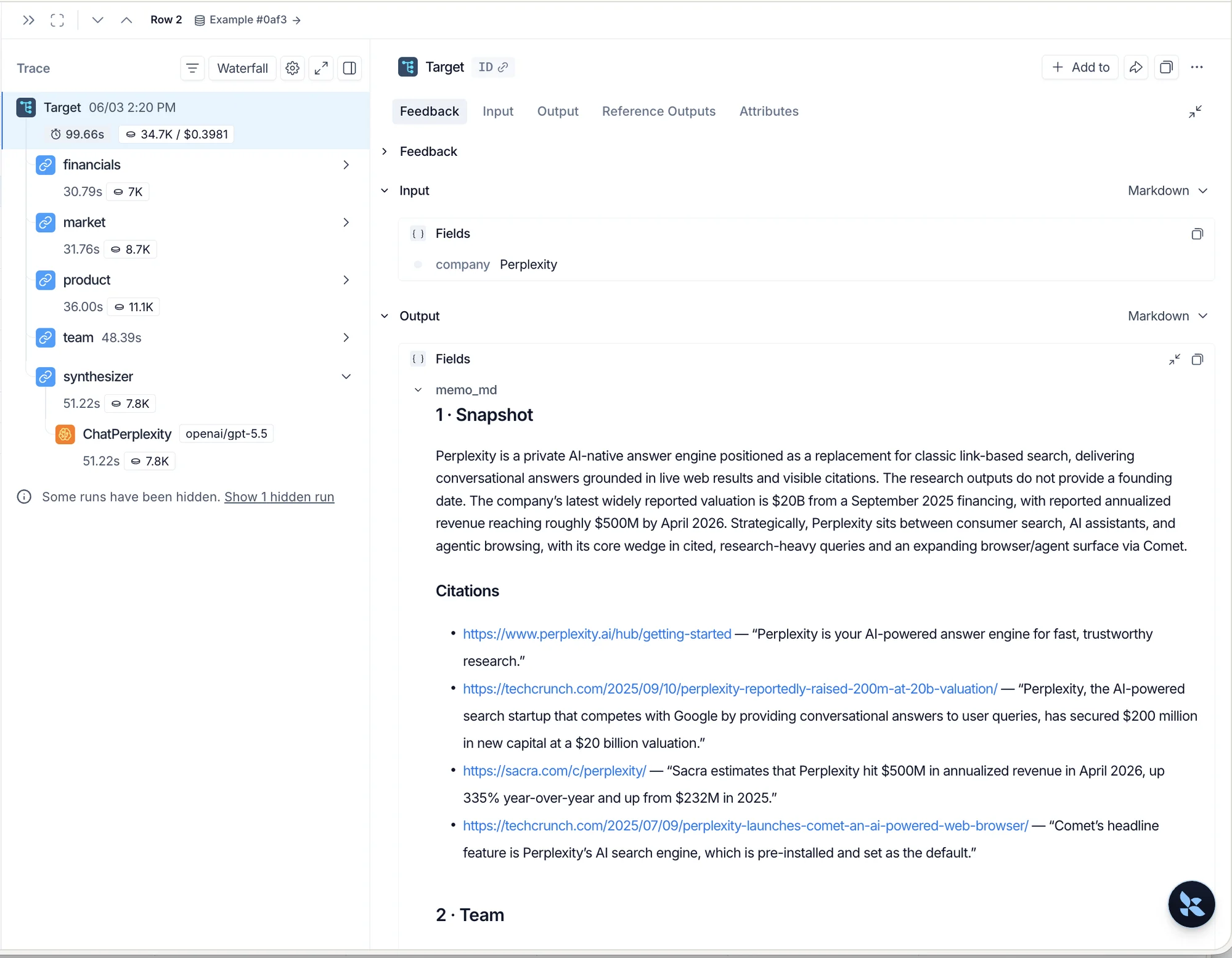
The synthesizer has no tools. It composes all seven memo sections from the four nodes’ research outputs, so every cited claim is grounded in research one of the nodes actually did. Sections 1–6 each end with a### Citations list pairing every source URL with the evidence it supports. The Thesis is the one analysis-only section, with no citations.
Wiring the graph
Four research nodes fan out fromSTART in parallel and converge on the synthesizer. The wiring is short:
Running it
LANGSMITH_TRACING="true", the full run appears in LangSmith with every node’s tool calls. Here is a public trace of one run to explore.
Choosing a search provider
Which search provider should back the agent?memo/profiles.py runs the same graph with three swappable client-side search tools (PerplexitySearchResults, ParallelSearchTool, ExaSearchResults), and memo/compare.py scores them in LangSmith so the same metrics apply to each.
Two custom evaluators score memo quality, alongside LangSmith’s built-in latency and cost:
primary_source_rate: share of citations from primary sources (IR pages, SEC, official press) rather than aggregators.financial_concept_coverage: whether the Financials section covers valuation, revenue, funding, and operating metrics.
Results
Scored across ten public and private companies onopenai/gpt-5.5:

Perplexity posted a perfect primary-source rate, the fastest memos, the lowest cost per run, and tied for the best financial-concept coverage on this run. Re-score the providers on your own dataset to see how they compare for your use case.
Directory structure
Insidedocs/articles/langchain-vc-memo-agent/ in api-cookbook:
Links
- Perplexity Agent API tools
- Finance Search
- LangChain Perplexity provider
- LangGraph
- LangSmith evaluation
Limitations
- Know where it falls short. The agent is only as strong as the primary sources it can find: solid for well-documented companies, shakier for thinly-covered private startups where little has been published.
- The section template is just a convention. The seven sections and the PASS / TRACK / ADVANCE / LEAD scale are the format we picked; swap in whatever your team uses.